- 赛项名称:2020 年第三届“全国大学生大数据技能竞赛”
- 面向群体:全国本科院校、高职院校在校生
- 主办单位:中国大数据技术与应用联盟
- 技术平台:北京红亚华宇科技有限公司 青椒课堂
# 背景目的
信息互联网的发展使人类进入了大数据智能时代,大数据技术的应用深刻 影响着人们的生活,影响着时代发展的进程。《纲要》中明确指出,要加强专业人才培养、创新人才培养 模式、建立健全的多层次多类型的大数据人才培养体系,目前各高校相继启动 大数据专业建设,大数据人才培养迈进了一个全新时代。
通过大赛,可以提高实践教学课时量,学生可在“大数据 竞赛平台”中以实际大数据项目案例开展训练相关技能并在平台搭建、数据采 集、数据分析与挖掘等方面得到有效锻炼,提高学生的专业技能并逐步实践 “理实一体化”、“做学教一体化”的教学模式。
# 培训笔记(第一周 6月7日)
- Liunx 环境配置JDK
- 配置 SSH 免密登录
- HDFS分布式集群搭建
- 搭建YARN伪分布式集群
- Hadoop集群初体验
# 一、 Liunx 环境配置JDK
# 1.1 准备
先准备好相应的jdk 安装包和Linux 操作环境
创建工作目录
mkdir -p /usr/java1下载软件
whet http://xxx/jdk-8u171-linux-x64.tar.gz1
了解基本的vi 操作
- 跳到最后面 => G
- 默认vi进入的就是非编辑模式下,当按a/i/o 后才进入编辑模式
- a:在光标所在字符后开始插入
- i:当前位置输入,在光标所在字符前开始插入(这个用的相对多)
- o:在光标所在行的下面另起一新行插入
- s: 删除光标所在的字符并开始插入
- 从编辑模式变为非编辑模式,按左上角ESC 键
- 保存操作:非编辑状态下,
:wq!,快捷键:shift + zz
# 1.2 解压JDK 安装包
cd /root/software # 切换到软件目录下
tar -zxvf jdk-8u221-linux-x64.tar.gz # 解压压缩包
2
注:tar -zxvf 是解压命令,对应压缩命令是tar -zxcf
解压后可通过一下命令删除软件包
rm -rf/usr/java/jdk-8u221-linux-x64.tar.gz
# 1.3 配置环境变量
vim /etc/profile # 打开环境配置文件
# 在文件末尾追加以下两行内容
export JAVA_HOME=/root/software/jdk1.8.0_221 # 配置Java的安装目录
export PATH=$PATH:$JAVA_HOME/bin # 在原PATH的基础上加入JDK的bin目录
2
3
4
5
# 1.4 立即生效文件并检查状态
source /etc/profile # 立即生效文件
java -version # 查看jdk 安装版本信息
2
# 二、配置 SSH 免密登录
这个步骤可以参考git 工具中配置公钥的步骤,目的就是将本机的公钥文件放置在别的机器的授权目录下,这样之后访问就不需要手动授权了。
# 2.1 下载 SSH 服务并启动
提前下载好SSH 服务(openssh-server 和 openssh-clients),在目录下运行
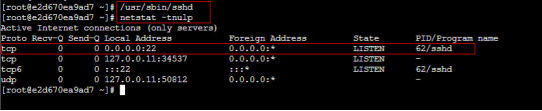
/usr/sbin/sshd
SSH 服务启动成功后,默认开启22(SSH 的默认端口)端口号,可以使用以下命令进行查看
netstat -tnulp
执行命令,可以看到22 号端口已经开启,证明我们 SSH 服务启动成功
# 2.2 生成密钥对
ssh-keygen
## 或者
ssh-keygen -t rsa
2
3
上面一种是简写形式,提示要输入信息时不需要输入任何东西,直接回车三次即可。
# 2.3 将公钥放置到授权列表文件 authorized_keys 中
cd /root/.ssh # 切换到ssh 根目录
cp id_rsa.pub authorized_keys # copy 文件数据
2
此时,通过ls命令查看文件copy 生成之后,就可以使用ssh 命令连接服务器了
hostname # 查看本机计算机名
ifconfig # 查看本机网络ip 信息
ssh 172.18.23.221 # 连接指定服务器
2
3
4
# 2.4 修改授权列表文件 authorized_keys 的权限
chmod 600 authorized_keys
# 2.5 验证免密登录是否配置成功
ssh localhost
## 或者
ssh e2d670ea9ad7
## 或者
ssh 10.141.0.42
2
3
4
5
# 2.6 退出命令
远程登录成功后,若想退出,可以使用exit命令。
# 三、HDFS分布式集群搭建
# 3.1 解压hadoop2.7.7 安装包
使用cd命令进入/root/software 目录下,使用如下命令解压 hadoop2.7.7 安装包:
tar -zxvf hadoop-2.7.7.tar.gz
# 3.2 配置环境变量 hadoop-env.sh
打开 hadoop-env.sh 文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
找到 JAVA_HOME 参数位置,修改为本机安装的 JDK 的实际位置。
# 3.3 配置核心组件 core-site.xml
使用如下命令打开“core-site.xml”文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/core-site.xml
将下面的配置内容添加到 <configuration> 标签中间:
<!-- HDFS集群中NameNode的URI(包括协议、主机名称、端口号),默认为 file:/// -->
<property>
<name>fs.defaultFS</name>
<!-- 用于指定NameNode的地址 -->
<value>hdfs://localhost:9000</value>
</property>
<!-- Hadoop运行时产生文件的临时存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopData/temp</value>
</property>
2
3
4
5
6
7
8
9
10
11
# 3.4 配置文件系统 hdfs-site.xml
使用如下命令打开“hdfs-site.xml”文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
将下面的配置内容添加到 <configuration> 标签中间:
<!-- NameNode在本地文件系统中持久存储命名空间和事务日志的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopData/name</value>
</property>
<!-- DataNode在本地文件系统中存放块的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopData/data</value>
</property>
<!-- 数据块副本的数量,默认为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 3.5 配置 Hadoop 系统环境变量
(1) 首先打开/etc/profile 文件(系统环境变量:对所有用户有效):
vim /etc/profile
(2) 在文件底部添加如下内容:
# 配置Hadoop的安装目录
export HADOOP_HOME=/root/software/hadoop-2.7.7
# 在原PATH的基础上加入Hadoop的bin和sbin目录
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2
3
4
(3) 让配置文件立即生效,使用如下命令:
source /etc/profile
(4) 检测 Hadoop 环境变量是否设置成功,使用如下命令查看 Hadoop 版本:
hadoop version
# 3.6 格式化文件系统
hdfs namenode -format
# 3.7 脚本一键启动 HDFS 集群
start-dfs.sh
# 3.8 查看进程启动情况
在本机上执行 jps 命令查看进程启动情况。
# 3.9 通过 UI 查看 HDFS 运行状态
通过本机的浏览器访问http://localhost:50070或http://本机IP 地址:50070查看 HDFS 集群状态。
# 四、搭建YARN伪分布式集群
# 4.1 配置环境变量 yarn-env.sh
使用如下命令打开“yarn-env.sh”文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-env.sh
找到 JAVA_HOME 参数位置,将前面的#去掉,将其值修改为本机安装的 JDK 的实际位置
# 4.2 配置计算框架 mapred-site.xml
在 $HADOOP_HOME/etc/hadoop/目录中默认没有该文件,需要先通过如下命令将文件复制并重命名为“mapred-site.xml”:
cp mapred-site.xml.template mapred-site.xml
接着,打开“mapred-site.xml”文件进行修改:
vim /root/software/hadoop-2.7.7/etc/hadoop/mapred-site.xml
将下面的配置内容添加到 中间:
<!-- 指定使用 YARN 运行 MapReduce 程序,默认为 local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2
3
4
5
# 4.3 配置 YARN 系统 yarn-site.xml
使用如下命令打开该配置文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-site.xml
将下面的配置内容加入 中间:
<!-- NodeManager上运行的附属服务,也可以理解为 reduce 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2
3
4
5
# 4.4 脚本一键启动 YARN 集群
start-yarn.sh
# 4.5 查看进程启动情况
在本机上执行 jps 命令查看进程启动情况。
# 4.6 通过 UI 查看 YARN 运行状态
通过本机的浏览器访问http://localhost:8088或http://本机IP 地址:8088查看 YARN 集群状态。
# 五、 Hadoop集群初体验
实验目标:在本机桌面(/headless/Desktop)上创建一个名为 inputdata 的文件夹,在此文件夹下新建一个名为 word.txt 的文本文件,并将该文件上传到 HDFS 的/wordcount/input(若没有则需手动创建) 目录下,作为 WordCount 示例的数据源。
# 5.1 启动 Hadoop 集群
(1)HDFS 集群
在本机上使用如下方式一键启动 HDFS 集群:
start-dfs.sh
(2)YARN 集群
在本机上使用如下方式一键启动 YARN 集群:
start-yarn.sh
# 5.2 WordCount 示例执行流程
(1)在本机桌面(/headless/Desktop)上创建一个名为 inputdata 的文件夹,在此文件夹下新建一个名为 word.txt 的文本文件,内容如下:
hadoop jar hadoop mapreduce
hadoop hdfs
hdfs hadoop jar fs
fs
2
3
4
注意单词之间用空格进行分隔
(2)接着,在 HDFS 上创建/wordcount/input 目录,并将 word.txt 文件上传至该目录下,具体指令如下所示:
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put /headless/Desktop/word.txt /wordcount/input
2
(3)进入$HADOOP_HOME/share/hadoop/mapreduce/目录下,使用 hadoop-mapreduce-examples-2.7.7.jar示例包,对 HDFS 上的 word.txt 文件进行单词统计,在 jar 包位置执行如下命令:
hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount \
/headless/Desktop/word.txt /wordcount/output
# 注意:\为换行指令(可以写成一行,不使用换行符)
2
3
4
(4)程序执行成功后,我们可以使用 HDFS Shell 的相关指令查看 part-r-00000 的内容,具体指令如下所示:
hadoop fs -cat /wordcount/output/part-r-00000
# 培训笔记(第二周 6月13日)
# 一、Hive 内嵌模式安装
# 1.1 解压安装包
现在已经为大家下载好了 hive2.3.4 的安装包,存放在 /root/software 目录下,首先进入此目录下,使用如下命令进行解压即可使用:
tar -zxvf apache-hive-2.3.4-bin.tar.gz
将其解压到当前目录下,即 /root/software 中。
# 1.2 配置环境变量
首先打开 /etc/profile 文件:
vim /etc/profile
将以下内容添加到配置文件的底部,添加完成输入“:wq”保存退出:
# 配置Hive的安装目录
export HIVE_HOME=/root/software/apache-hive-2.3.4-bin
# 在原PATH的基础上加入Hive的bin目录
export PATH=$PATH:$HIVE_HOME/bin
2
3
4
注意:
- export 是把这两个变量导出为全局变量。
- 大小写必须严格区分。
(3)让配置文件立即生效,使用如下命令:
source /etc/profile
检测 Hive 环境变量是否设置成功,使用如下命令查看 Hive 版本:
hive --version
执行此命令后,若是出现 Hive 版本信息说明配置成功:

# 二、内嵌模式安装
# 2.1 修改配置文件 hive-env.sh
切换到 ${HIVE_HOME}/conf 目录下,将 hive-env.sh.template 文件复制一份并重命名为 hive-env.sh:
cp hive-env.sh.template hive-env.sh
修改完成,使用 vi 编辑器进行编辑:
vim hive-env.sh
在文件中配置 HADOOP_HOME、HIVE_CONF_DIR 以及HIVE_AUX_JARS_PATH 参数:
# 配置Hadoop安装路径
HADOOP_HOME=/root/software/hadoop-2.7.7
# 配置Hive配置文件存放路径
export HIVE_CONF_DIR=/root/software/apache-hive-2.3.4-bin/conf
# 配置Hive运行资源库路径
export HIVE_AUX_JARS_PATH=/root/software/apache-hive-2.3.4-bin/lib
2
3
4
5
6
7
8
配置完成,输入“:wq”保存退出。
# 2.2 初始化元数据库
注意:当使用的 Hive 是 2.x 之前的版本时,不做初始化也是 OK 的。Hive 第一次启动时会自动进行初始化,只不过不会生成足够多的元数据库的表,其它的在使用过程中会慢慢生成。如果使用的是 2.x 版本的 Hive,那么就必须手动初始化元数据库。 使用如下命令进行初始化,这里我们使用 Hive 默认的 db 类型 “derby”:
schematool -dbType derby -initSchema
若是出现“schemaTool completed”则初始化成功,如下图所示:

初始化完成,会在当前目录下生成一个 derby.log 文件和一个 metastore_db 目录。
# 2.3 Hive 连接
在此目录下使用 Hive 的三种连接方式之一:CLI 启动 Hive。由于已经在环境变量中配置了 HIVE_HOME ,所以这里直接在命令行执行如下命令即可:
hive
或者
hive --service cli
2
3
效果如下图所示:

# 三、安装 MySQL
# 3.1 解压安装包
现在已经为大家下载好了 MySQL 5.7.25 的安装包,存放在 /root/software 目录下,首先进入此目录下,使用如下命令进行解压即可使用:
tar -xvf mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar
将其解压到当前目录下,即 /root/software 中。
# 3.2 安装 MySQL 组件
使用 rpm -ivh 命令依次安装以下组件:
(1)首先安装mysql-community-common (服务器和客户端库的公共文件),使用命令:
rpm -ivh mysql-community-common-5.7.25-1.el7.x86_64.rpm
(2)其次安装mysql-community-libs(MySQL数据库客户端应用程序的共享库),使用命令:
rpm -ivh mysql-community-libs-5.7.25-1.el7.x86_64.rpm
(3)之后安装 mysql-community-libs-compat(MySQL 之前版本的共享兼容库),使用命令:
rpm -ivh mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm
(4)之后安装 mysql-community-client(MySQL客户端应用程序和工具),使用命令:
rpm -ivh mysql-community-client-5.7.25-1.el7.x86_64.rpm
(5)最后安装 mysql-community-server(数据库服务器和相关工具),使用命令:
rpm -ivh mysql-community-server-5.7.25-1.el7.x86_64.rpm
# 3.3 登录 MySQL
(1) 初始化 MySQL 的数据库
安装好 MySQL 后,我们需要初始化数据库,初始化和启动数据库时最好不要使用root用户,而是使用mysql用户启动。
/usr/sbin/mysqld --initialize-insecure --user=mysql
(2) 启动 MySQL 服务
使用如下命令开启 MySQL 服务,让其在后台运行:
/usr/sbin/mysqld --user=mysql &
说明:一定要加“&”,才能脚本放到后台运行。
(3) 登录 MySQL
使用root用户无密码登录 MySQL:
mysql -uroot
(4) 重置 MySQL 密码
在 5.7 版本后,我们可以使用 alter user...identified by命令把root用户的密码修改为“123456”,具体命令如下所示:
mysql> alter user 'root'@'localhost' identified by '123456';
效果如下图所示:

# 3.4 增加远程登录权限
当我们的帐号不允许从远程登录,只能在localhost连接时。这个时候只要在 MySQL 服务器上,更改mysql 数据库里的 user 表里的 host 项,从localhost改成%即可实现用户远程登录。
(1) 首先我们来查看 mysql 数据库下的 user表信息:
mysql> use mysql; # 切换成mysql数据库
mysql> select user,host from user; # 查询用户信息
2
可以看到在user表中已创建的root用户。host字段表示登录的主机,其值可以用IP地址,也可用主机名。
(2)实现远程连接(授权法)
将 host 字段的值改为%就表示在任何客户端机器上能以root用户登录到 MySQL 服务器,建议在开发时设为%。
# 设置远程登录权限
mysql> update user set host='%' where host='localhost';
# 刷新配置信息
mysql> flush privileges;
2
3
4
效果图如下所示:

# 四、Hive 安装部署
# 4.1 解压安装包
现在已经为大家下载好了 hive2.3.4 的安装包,存放在 /root/software 目录下,首先进入此目录下,使用如下命令进行解压即可使用:
tar -zxvf apache-hive-2.3.4-bin.tar.gz
将其解压到当前目录下,即 /root/software 中。
# 4.2 配置环境变量
(1) 首先打开 /etc/profile 文件:
vim /etc/profile
(2) 将以下内容添加到配置文件的底部,添加完成输入“:wq”保存退出
# 配置Hive的安装目录
export HIVE_HOME=/root/software/apache-hive-2.3.4-bin
# 在原PATH的基础上加入Hive的bin目录
export PATH=$PATH:$HIVE_HOME/bin
2
3
4
(3) 让配置文件立即生效,使用如下命令:
source /etc/profile
(4) 检测 Hive 环境变量是否设置成功,使用如下命令查看 Hive 版本
hive --version
执行此命令后,若是出现 Hive 版本信息说明配置成功:
# 4.3 修改配置文件 hive-env.sh
切换到 ${HIVE_HOME}/conf 目录下,将 hive-env.sh.template 文件复制一份并重命名为 hive-env.sh
cp hive-env.sh.template hive-env.sh
修改完成,使用 vi 编辑器进行编辑:
vim hive-env.sh
在文件中配置 HADOOP_HOME、HIVE_CONF_DIR 以及HIVE_AUX_JARS_PATH 参数:
# 配置Hadoop安装路径
HADOOP_HOME=/root/software/hadoop-2.7.7
# 配置Hive配置文件存放路径
export HIVE_CONF_DIR=/root/software/apache-hive-2.3.4-bin/conf
# 配置Hive运行资源库路径
export HIVE_AUX_JARS_PATH=/root/software/apache-hive-2.3.4-bin/lib
2
3
4
5
6
7
8
配置完成,输入“:wq”保存退出。
# 五、Hive元数据配置到MySQL
# 5.1 驱动拷贝
将/root/software目录下的 MySQL 驱动包 mysql-connector-java-5.1.47-bin.jar 拷贝到 ${HIVE_HOME}/lib 目录下。
cd /root/software/
cp mysql-connector-java-5.1.47-bin.jar apache-hive-2.3.4-bin/lib/
2
# 5.2 配置 Metastore到MySQL
(1)在${HIVE_HOME}/conf目录下创建一个名为hive-site.xml的文件,并使用vi编辑器进行编辑:
touch hive-site.xml
vim hive-site.xml
2
(2)根据官方文档配置参数(https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration),拷贝数据到 hive-site.xml 文件中:
<configuration>
<!--连接元数据库的链接信息 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<!--连接数据库驱动 -->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--连接数据库用户名称 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!--连接数据库用户密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 5.3 初始化元数据库
注意:如果使用的是 2.x 版本的 Hive,那么就必须手动初始化元数据库。 使用 schematool -dbType <db type> -initSchema 命令进行初始化:
schematool -dbType mysql -initSchema
若是出现“schemaTool completed”则初始化成功。

# 5.4 Hive 连接
在任意目录下使用 Hive 的三种连接方式之一:CLI 启动 Hive。由于已经在环境变量中配置了 HIVE_HOME ,所以这里直接在命令行执行如下命令即可:
hive
或者
hive --service cli
2
3
效果如图所示:

可以使用如下命令退出 Hive 客户端
hive> exit;
或者
hive> quit;
2
3
# 5.5 Hive 常见属性配置
(1)首先,将 ${HIVE_HOME}/conf 目录下的 hive-log4j2.properties.template 文件复制一份并重命名为 hive-log4j2.properties,具体命令如下所示:
cp hive-log4j2.properties.template hive-log4j2.properties
(2)之后使用 vi 编辑器进行编辑,将 Hive 日志配置到 /root/hive/logs/myhive.log 文件中。用到的两个参数是:
- property.hive.log.dir
- property.hive.log.file
(3)重新启动 Hive:
hive
或者
hive --service cli
2
3
4)验证新的日志文件是否自动创建:

从上图可以看出,我们成功将 Hive 日志存放路径修改为 /root/hive/logs/myhive.log。
# 培训笔记(第三周 6月20日)
# 一、操作:论坛数据爬取
开启服务(密码:qingjiao):
- sudo service apache2 start
- sudo service mysql start
终端查看环境所需库:
- pip list
浏览器访问本地IP
requests练习:
import requests
response = requests.get('URL') #请求目标网站
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
2
3
4
5
6
7
8
9
10
11
12
13
14
15
xpath练习:
import requests
from lxml import etree #导入lxml库的etree模块
url = 'http://localhost/home.php?mod=space&uid=435'
reponse = requests.get(url)
html = reponse.text
print(html) #获得源码
#加载整个文档进行解析
element = etree.HTML(html) #声明HTML文本,调用HTML类进行初始化
username = element.xpath('//*[@id="uhd"]/div[2]/h2') #根据xpath路径,定位目标数据
print(username) #打印变量
#[<Element h2 at 0x7fdb20940e10>] #列表
#通过索引值来访问特定的子元素
print(username[0].text) #文本
#qaFiioH
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17